Why Pure Vector Seach Is Almost Never Enough
21/01/2026

When Semantic Search Stops Being Semantic
I searched my personal knowledge base for “gpt-oss”—a specific open-source model I had been experimenting with in my homelab.
ChatGPT responded: “I am only seeing notes about your Authentik migration”. I checked the response, 51% similarity. Completely unrelated.
I asked Claude, “Pull my letter to Mrs Modupe”—looking for correspondence with my relationship counsellor. Claude said it only found Kubernetes infrastructure docs. 41% similarity.
Pure vector search wasn’t finding related concepts. It was just… guessing.
Why Vector Search Seemed Like the Obvious Choice
I am building Knowmeld, an AI Knowledge platform that lets ChatGPT and Claude access your personal notes without vendor lock-in. The architecture was textbook RAG:
Embed documents → Store in pgvector → Cosine similarity search → Return top chunks.
Simple. Elegant. Works 60% of the time, every time.
And it worked beautifully in the demos. Ask “What are my thoughts on Kubernetes?” Get relevant notes about container orchestration, deployment strategies, infrastructure decisions.
Semantic search excels at this. Related concepts cluster together in vector space even when expressed with different words.
The problem only revealed itself when I started dogfooding my own product.
The Breaking Point: Real Queries on Real Data
I use Knowmeld to search my engineering logbook while writing. That’s when I noticed the pattern.
Generic conceptual queries? Perfect. Specific technical searches? Catastrophic failure.
Examples of what broke:
- “How did I fix DNS in k3s?” → Authentik docs (47%)
- “gpt-oss setup” → Random infrastructure notes (32%)
- “Longhorn migration decision” → Unrelated CouchDB content (40%)
The pattern: My knowledge base is full of specifics—project names, error messages, technical comands, people’s names. Vector embeddings are too semantic for this. They find “things vaguely about GPT” when I need “the exact note about gpt-oss.”
The system always returned something. Never admitted “I don’t know.” Just confidently served garbage with mediocre similarity scores.
The Solution: Hybrid Search (Not “Admitting Defeat”)
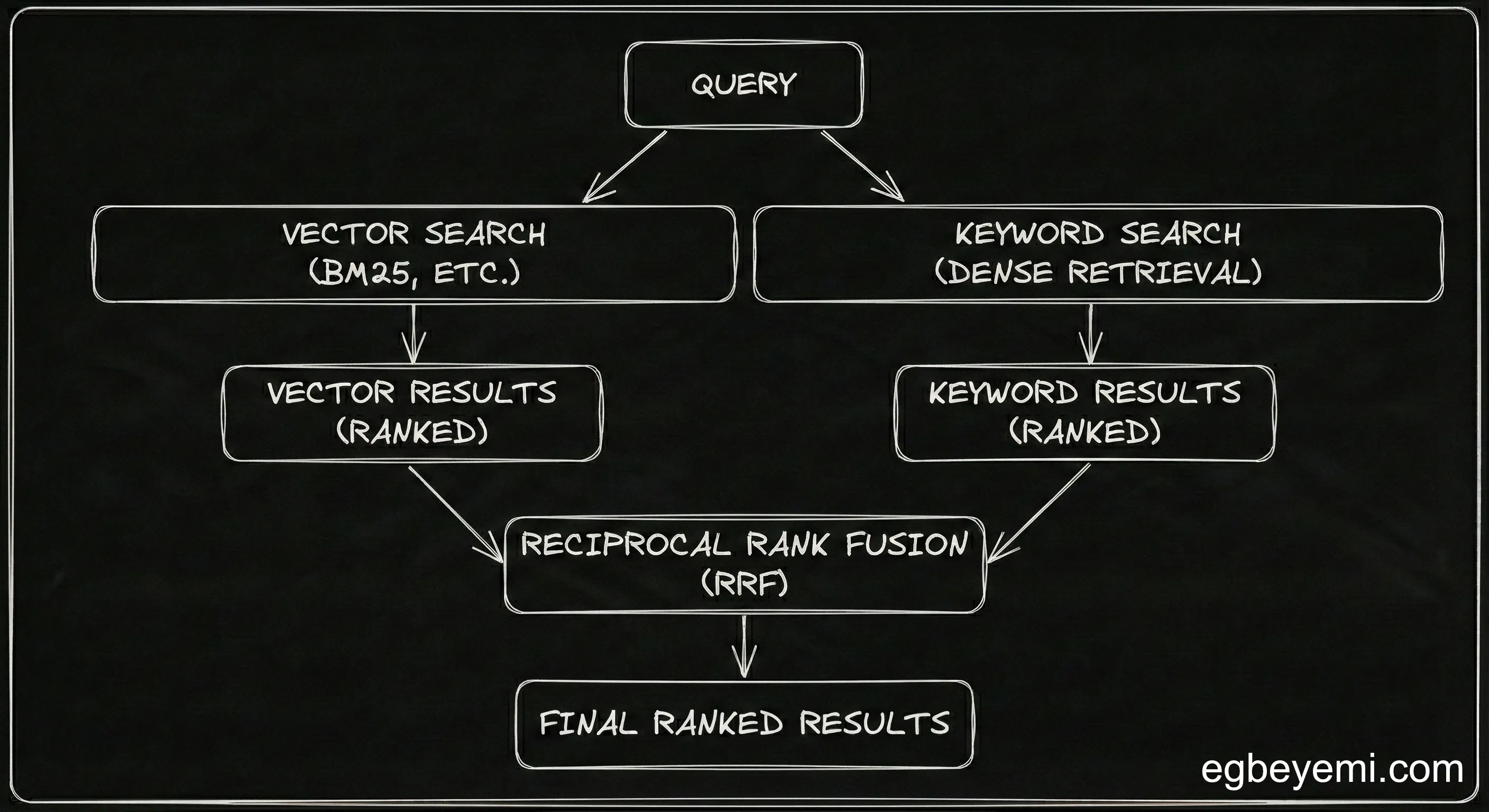
Hybrid search wasn’t plan B. It was realising that I had been using a knife to drive Phillip screws.
Vector search handles concepts beautifully. BM25 handles precision perfectly
Why choose?
I evaluated ParadeDB’s pg_search (8.2k stars) vs TimescaleDB’s pg_textsearch (2.2k stars). Went with ParadeDB for better docs and more active development.
Setup:
CREATE EXTENSION IF NOT EXISTS pg_search;
CREATE INDEX idx_chunk_content_bm25 ON document_chunk
USING bm25 (id, content) WITH (
key_field = 'id',
text_fields = '{"content": {"tokenizer": {"type": "default"}}}'
);The query combines both approaches using Reciprocal Rank Fusion—chunks that rank well in both semantic AND keyword search get boosted. Score threshold filters out weak matches.
One gotcha: ParadeDB’s CNPG helm chart requires an enterprise licence for high availability. I built a custom docker image instead.
The Results
Same queries. Completely different outcomes.
- “gpt-oss” → Direct hit: “Getting gpt-oss 20 on llama.cpp” (My note)
- “Letter to Mrs Modupe” → Exact document: relationship counselling correspondence
- “DNS k3s fix” → “Postmortem: DNS failure in the cluster”
From my implementation notes:
The results were mindblowing. Even with short queries, keyword heavy queries, the chunks returned were stupid fucking relevant.
Excuse my French.
What This Means If You’re Building RAG
Vector embeddings are powerful for:
- Conceptual similarity (“What did I write about authentication”)
- Cross-lingual retrieval
- Finding Ideas expressed differently
They fail for
- Technical terms, names, IDs
- Specific commands or errors
- Short keyword queries
- Anything requiring exact matching
Hybrid search gives you both. It is not more complex—if you are running pgvector, adding ParadeDB is straightforward.
Key principles:
- Don’t trust similarity scores below 0.7
- Implement score thresholds to reject garbage
- Return “no results” instead of confidently wrong answers
- Test with real user queries, not synthetic examples
Try it Yourself
Knowmeld runs hybrid search in production across Claude Desktop, ChatGPT and our MCP server. Register interest at knowmeld.io ob
Want to talk about Software/AI Infrastructure?