2025: From Matching Candidates to Melding Knowledge
31/12/2025
There is a specific kind of silence that falls over a house when the DNS server goes down.
I wrote about that earlier this month—a post-mortem on my Monolithic Homelab and the lessons learned in the trenches of Proxmox, corrupted partitions, and self-inflicted outages.
But as 2025 draws to a close, I find myself looking at a much larger architectural failure beyond my home network.
This failure is in how we interact with Artificial Intelligence.
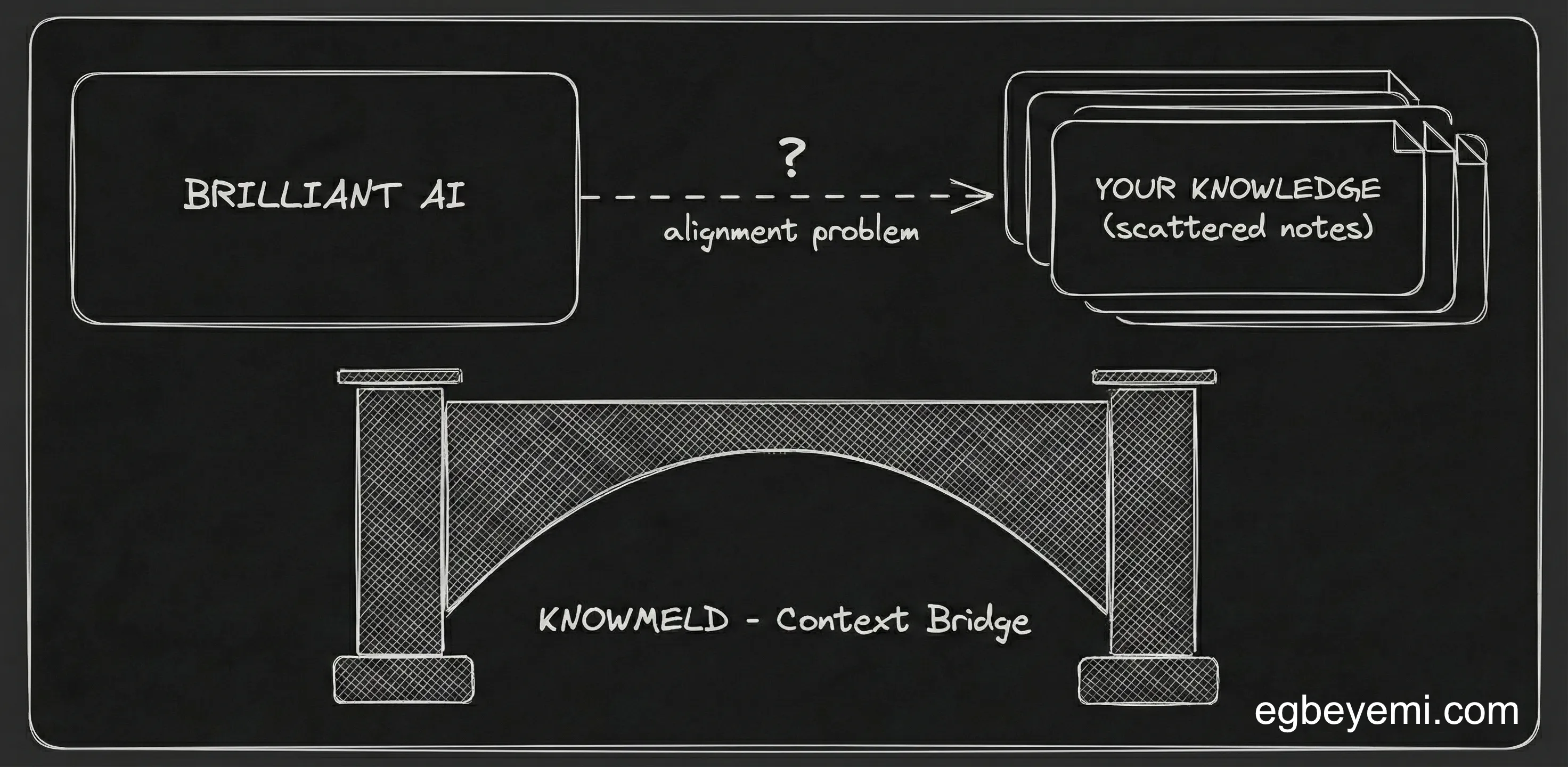
The Autometry Lesson: The Alignment Problem
I spent the entirety of 2025 at Autometry. We were building high-performance matching engines for the recruitment industry. The challenge was classic Big Data: how do you take tens of thousands of unstructured, messy human life stories (resumes) and align them with the rigid (and often vibes-based) requirements of a job description?
We built semantic search layers. Retrieval pipelines. Reasoning agents. We obsessed over precision, recall, embedding dimensionality, and evaluation metrics.
But as the market for recruitment tech shifted, and the company began to scale back, I had an epiphany.
The Alignment Problem isn’t just for recruiters.
It’s for all of us.
The Brilliant (Amnesiac) Stranger
We have entered the age of the Brilliant Stranger (with amnesia).
We now have access to LLMs that can write complex Python, reason across domains and pass the Bar exam. Yet they are fundamentally blind to our personal context. Worse till, they quickly forget it when you give them that context.
My Obsidian vault is my “Second Brain”. It contains years of project logs—stretching back to my doctorate—architectural decisions, experiments, and half formed ideas.
My Notion workspace is my External Memory.
Yet, when I talk to ChatGPT or Claude, I have to start from zero.
I have to copy-paste my life to a prompt box, hoping the context window doesn’t cut me off, or that I have selected the right notes this time. The burden of alignment is entirely on me.
We have spent billions making AI smarter, but we haven’t made it know us.
Turning the Search Inward
As I start my gardening leave, I’m not spending the time polishing my CV for another corporate role.
I am going back to the lab.
I have traded 8 a.m. stand-ups for 2 a.m. debugging sessions. Meeting rooms for a 3-node Kubernetes cluster under my stairs.
I am building Knowmeld.
Knowmeld is a Context Bridge. It is the application of everything I learned over the past several years about high performance retrieval—this time focused on the individual.
It connects your private data stores—starting with Obsidian—directly to your AI platforms, without the friction of manual uploads or the insecurity of shared API keys.
The Architecture of Trust
I am building this as a technical founder first. That means no generic wrappers, no magical abstractions, and no “best effort” security.
Atomic Precision
I hand-rolled a recursive Markdown chunker because generic libraries were butchering the structure of my notes. Headers matter. Code blocks are atomic. Structure is meaning. If AI can’t respect how you think, it can’t help you think.
Sovereign Infrastructure
Knowmeld runs on private, multi-tenant K8s infrastructure. Data is stored in PostgreSQL with PGVector and enforced with Row-Level Security (RLS). Extreme data isolation is the baseline, not a feature.
Zero-Training Architecture
Your knowledge is used as your context, never as training data. You are not the product.
2026: The Year of the Bridge
Today, I registered Knowmeld Ltd.
In 14 days, I am launching the first bridge: Obsidian → ChatGPT.
It will be a paid, premium service because professional-grade infrastructure isn’t free. Your data should not be subsidising someone else’s business model.
2025 was a year for matching candidates to jobs.
2026 will be the year of melding knowledge with potential.
Happy New Year.
Let’s build something that matters.
Want to talk about Software/AI Infrastructure?